







AI 见闻日报:连华尔街都低估了英伟达的业绩,生成式 AI 需求突破想象力 | 见智研究
1、英伟达 Q2 业绩指引超华尔街预期 53%,生成式 AI 的需求被低估; 2、英特尔公布 Aurora genAI 大模型,参数是 ChaGPT 的近 6 倍; 3、开源模型鼻祖 Meta 又开源了 MMS,识别 4 千种语言。
今日要闻:
1、华尔街都低估了生成式 AI 的跨行业需求,英伟达 Q2 业绩指引超华尔街预期 53%,AI 超级计算系统将为英伟达带来更多超额收益;
2、英特尔公布 Aurora genAI 大模型,参数是 ChaGPT 的近 6 倍,多规格参数模型是平衡成本和效率的 “最优解”;
3、Meta 又开源一个多语种语音大模型 MMS,能识别 4 千种语言,生成 1 千种语音;
4、斯坦福等学者发布机器视觉跟踪重大突破,SiamMAE 能节省高昂费用;
见闻视角
1、华尔街都低估了生成式 AI 的跨行业需求,AI 超级计算系统将为英伟达带来更多超额收益。
英伟达 Q1 财报大超预期成为今日瞩目焦点,更重要的是Q2 的业绩指引将成为该公司有史以来最高的季度营收,超过华尔街预期的 53.2%。
英业达业绩超预期背后,最大的贡献来自于四大业务中的数据中心业务,收入创历史新高,达到 42.8 亿美元,同比增长 14%,环比增长 18%。此外汽车业务虽然占比较小,但也达到了同环比的增长速度。而游戏和专业可视化的需求显然还没有恢复到去年同期水平。
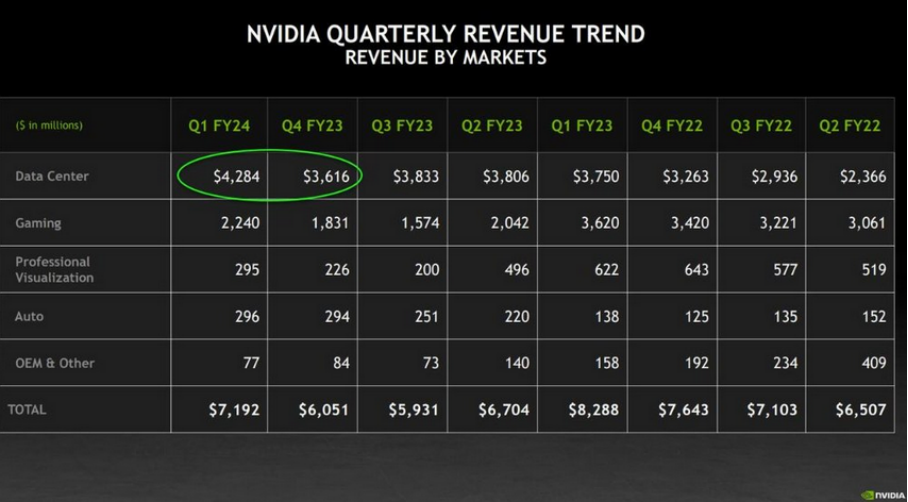
见智研究认为:市场远远低估了生成式 AI 需求,AI 超级计算系统将为英伟达带来更多超额收益。
英伟达数据中心收入激增主要是由于生成式 AI 和大语言模型的需求不断增长,从而带动公司基于 Hopper 和 Ampere 架构的 GPU 需求超预期。目前数据中心产品需求能见度延长了几个季度之多,在下半年 H100 的供应量还将会进一步增长。
从客户需求来看:云计算服务供应商、消费者网络公司以及企业客户都希望尽快将生成式 AI 套用到现有业务中。而根据订单排期的情况来看,GPU 全年都将呈现供不应求的局面。因而预计英伟达的收入会持续受益于生成式 AI 所带动的数据中心业务增长。
生成式 AI 对于更个行业来说是颠覆性的存在,并且处于从无到有的起步阶段,能够创造的价值空间想象力非常大。
根据 Gartner 预测到 2025 年,使用生成式 AI 技术系统研发的新药和材料比例将从现在的 0% 上升到 30%+ 上,而这只是其众多行业用例之一。此外,生成式 AI 技术还在芯片、零件设计、合成数据等众多领域带来全新的价值。

值得关注的是,生成式 AI 正在推动计算需求呈现指数级增长,并快速过渡到英伟达的加速计算。公司也表示将开始销售 AI 超级计算系统给支付更多溢价的科技公司。
目前英伟达具有高性能网络方面的条件优势,并且在计算结构、内存调用、以及通信效率和速度方面做进一步的优化,同时会提高对高性能交换机、光模块以及光线的需求。
2、英特尔公布 AI 大模型 Aurora genAI,参数是 ChatGPT 的近 6 倍,多规格参数模型是平衡成本和效率的 “最优解”。
英特尔公布了旗下生成式 AI 大模型 Aurora genAI,该模型参数量高达 1 万亿,是 ChatGPT 的近 6 倍(参数量 1750 亿),依赖于 Megatron 和 DeepSpeed 框架,这些结构增强了模型的强度和容量。
Aurora genAI 模型是一个纯粹以科学为中心的生成式 AI 模型,主要用于科研;运行在英特尔为阿拉贡国家实验室开发的 Aurora 超算上,其性能达到了 200 亿亿次,是当前 TOP500 超算冠军 Frontier 的 2 倍。
见智研究认为:作为 ChatGPT 的有力竞争者,Aurora genAI 的公布预示着 AI 大模型赛道又迎来了新的重磅玩家,并极有可能在未来对各种科学领域产生重大影响。
同样值得关注的是,LLM 模型的研发会持续在扩大训练参数上内卷,但是越大体量模型的运行必然会产生更高的成本,当前如何在有效需求和成本之间的平衡成为大模型开发商值得重点关注的问题,要防止模型在应用时由于参数冗余而产生不必要的运行成本,所以大模型开发商推出多元化参数模型用于专项领域会成为必然的发展路径。
AI 快讯
1、Meta 又开源一个多语种语音大模型 MMS,能识别 4 千种语言
Meta 在 GitHub 上再次开源了一款全新的 AI 语言模型——Massively Multilingual Speech (MMS,大规模多语种语音),这款新的语言模型可以识别 4000 多种口头语言并生成 1100 多种语音(文本到语音)。上线短短的几个小时,在 GitHub 库便收获了 23kStar,Fork 数量高达 5.5k。
Meta 被看作大模型研发的一大黑马,是开源大模型的鼻祖,此前发布的 LLaMA 是被微调最多的通用模型。此前公司的 SAM 视觉模型为 CV 领域投下重磅炸弹,公司在开源多模态领域上的持续发力,进一步为开源社区提供强有力的技术支持。
2、斯坦福&普林斯顿大学学者发现计算机视觉跟踪新技术,能够节省高昂费用
在计算机视觉中,建立图像或场景之间的对应关系是一个重要的挑战,尤其是考虑到遮挡、视角变化和物体外观的变化。
来自斯坦福&普林斯顿大学学者联合发布的一篇名为【Siamese Masked Autoencoders】的论文中,发表了一种用于视频学习的蒙面自动编码器,SiamMAE 用于从视频中学习视觉对应关系,可以在没有显式标签或注释的情况下使得机器进行自主学习。学习到的表示可以用于视频分类、动作识别或对象跟踪等下游任务。

通过 SiamMAE 学习到的特征在视频对象分割、姿态关键点传播和语义部分传播等自监督方法中表现非常出色。该方法在标注数据稀缺或获取数据成本高昂的情况下特别有用。